在BERT中引入知識圖譜信息的若干方法及其在通信與自動控制技術研究中的應用
知識圖譜作為結構化的知識庫,能夠為自然語言處理模型提供豐富的先驗知識和實體間的語義關系。將知識圖譜信息引入BERT等預訓練語言模型,可以有效增強模型對世界知識的理解與推理能力,從而在復雜任務(如通信協(xié)議理解、自動控制指令解析)中取得更優(yōu)性能。本文旨在探討在BERT中引入知識圖譜信息的若干主流方法,并分析其在通信與自動控制技術研究領域的潛在應用價值。
一、在BERT中引入知識圖譜信息的主要方法
- 知識增強的預訓練(Knowledge-Enhanced Pre-training)
- 核心思想:在BERT的原始掩碼語言模型(MLM)預訓練目標基礎上,融入知識圖譜相關的預訓練任務,使模型在預訓練階段即學習到結構化知識。
- 典型方法:
- ERNIE(清華版/百度版):通過實體掩碼與實體關系預測等任務,將實體及其關系知識融入模型表示。
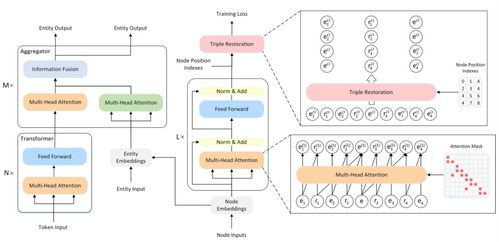
- K-BERT:將知識圖譜中的三元組(頭實體,關系,尾實體)以可見但不會被掩碼的“句子樹”形式注入到輸入句子中,使模型在推理時能直接“看到”相關知識。
- WKLM:在預訓練時用知識圖譜中同類型的其他實體替換文本中的實體,并讓模型判斷實體是否被替換,以學習實體知識。
- 知識注入的微調(diào)(Knowledge-Injected Fine-Tuning)
- 核心思想:在針對下游任務對BERT進行微調(diào)時,將外部知識圖譜的信息作為額外的輸入或約束,動態(tài)地增強模型在特定任務上的表示。
- 典型方法:
- 顯式注入:將知識圖譜中相關實體的嵌入(如TransE、TransR等知識圖譜嵌入方法得到的向量)與BERT的詞向量進行拼接或注意力融合,作為下游任務模型的輸入。
- 隱式約束:在微調(diào)的目標函數(shù)中加入基于知識圖譜的正則化項,例如,使模型對知識圖譜中相關的實體產(chǎn)生更相似的表示,或使其預測結果符合知識圖譜中的邏輯規(guī)則。
- 知識引導的注意力機制(Knowledge-Guided Attention)
- 核心思想:改造或引導BERT內(nèi)部的注意力機制,使其在計算注意力權重時,不僅考慮文本內(nèi)的語義關聯(lián),還考慮知識圖譜中實體間的結構化關系。
- 典型方法:
- 在圖結構上計算注意力:先將文本中的實體與知識圖譜對齊,然后在由文本序列和關聯(lián)知識子圖構成的異構圖(heterogeneous graph)上運行圖注意力網(wǎng)絡(GAT),將更新的實體表示與BERT的上下文表示融合。
- 注意力偏置:在BERT的自注意力計算中,加入一個基于知識圖譜實體關系先驗的偏置矩陣,引導模型更多關注在知識空間中有聯(lián)系的詞或?qū)嶓w。
- 檢索增強型方法(Retrieval-Augmented Methods)
- 核心思想:不直接修改BERT模型參數(shù),而是在推理時,從大型知識圖譜中檢索與輸入文本相關的知識片段(如相關實體、關系路徑或事實描述),將其作為額外的上下文與原始輸入一同輸入給BERT進行處理。這種方法靈活且無需重新預訓練。
二、在通信與自動控制技術研究中的應用潛力
將上述知識與BERT結合的方法應用于通信與自動控制領域,可望解決該領域文本處理中的若干關鍵挑戰(zhàn):
- 通信協(xié)議與標準文檔的深度理解:
- 應用場景:理解3GPP、IETF等組織發(fā)布的復雜技術標準文檔。
- 方法應用:構建通信領域的知識圖譜(包含協(xié)議實體、消息類型、參數(shù)、狀態(tài)機等),通過知識增強的預訓練或微調(diào)方法,使BERT模型能精準理解協(xié)議實體間的約束關系(如“消息A必須在狀態(tài)S下發(fā)送”),從而輔助協(xié)議一致性測試、漏洞分析或自動代碼生成。
- 工業(yè)控制指令與日志的語義解析:
- 應用場景:解析PLC編程指令、機器人控制命令或系統(tǒng)運行日志。
- 方法應用:建立控制領域知識圖譜(包含設備、傳感器、執(zhí)行器、控制邏輯、故障模式等)。利用知識注入的微調(diào)方法,可以增強BERT對模糊或簡寫指令的魯棒性理解,準確映射到知識圖譜中的具體操作或設備狀態(tài)。例如,將自然語言指令“提高泵速”準確關聯(lián)到知識圖譜中的特定泵實體及其速度參數(shù)。
- 故障診斷與根因分析:
- 應用場景:基于設備維護報告、警報文本進行自動化故障診斷。
- 方法應用:結合設備拓撲與故障傳播知識圖譜,采用知識引導的注意力或檢索增強方法,使BERT在分析故障描述時,能關聯(lián)到可能的故障組件鏈,提高診斷的準確性和可解釋性。
- 跨模態(tài)技術文檔處理:
- 應用場景:關聯(lián)技術說明書(文本)、電路圖/拓撲圖(圖像)與控制代碼(代碼)。
- 方法應用:知識圖譜可作為連接不同模態(tài)信息的橋梁。通過將多模態(tài)信息對齊到統(tǒng)一的知識圖譜中,再利用知識增強的BERT處理文本部分,可以實現(xiàn)更精準的圖文互檢、代碼注釋生成或設計文檔合規(guī)性檢查。
三、挑戰(zhàn)與展望
盡管前景廣闊,但在通信與自動控制這一高專業(yè)、高可靠性要求的領域應用知識增強的BERT仍面臨挑戰(zhàn):
- 領域知識圖譜構建:構建高質(zhì)量、覆蓋全面的領域知識圖譜需要大量專家知識,成本高昂。
- 知識噪聲與時效性:引入的外部知識可能存在噪聲或過時(如協(xié)議版本更新),可能對模型產(chǎn)生誤導。
- 模型復雜性與實時性:許多知識注入方法增加了模型復雜度和計算開銷,在需要實時響應的控制場景中可能受限。
- 可解釋性與安全性:在安全攸關的控制系統(tǒng)中,模型的決策必須可解釋、可驗證。知識增強雖可能提升可解釋性,但其可靠性仍需嚴格驗證。
未來研究方向可能包括:開發(fā)更高效輕量的知識注入方法;探索持續(xù)學習機制以動態(tài)更新模型中的知識;以及構建面向通信與自動控制的基準測試數(shù)據(jù)集,以更準確地評估知識增強模型在該領域的性能。
結論
將知識圖譜信息引入BERT模型,通過預訓練增強、微調(diào)注入、注意力引導等多種技術路徑,顯著提升了模型對結構化知識的利用能力。在通信與自動控制這一知識密集型的技術研究領域,此類方法為深度理解技術文檔、智能解析控制指令、精準進行故障診斷等任務提供了新的強大工具。盡管存在領域知識構建、模型復雜性等挑戰(zhàn),但隨著知識圖譜與預訓練模型技術的不斷融合與發(fā)展,其在推動通信與自動控制技術智能化進程方面必將發(fā)揮越來越重要的作用。
如若轉(zhuǎn)載,請注明出處:http://m.harbinvictories.cn/product/10.html
更新時間:2026-05-28 13:07:36